
Designed a multi-agent AI workflow to streamline qualitative analysis, introducing structured evaluation and critique to improve the reliability of research insights.
Qualitative thematic analysis is widely used in healthcare research to uncover patterns in patient and caregiver experiences.
However, traditional workflows are manual, time-consuming, and often inconsistent across researchers, making it difficult to scale insights.
In this project, we designed a multi-agent AI system to automate the thematic analysis process. By structuring the workflow into specialized agents, generation, evaluation, critique, and refinement, I aimed to improve both the efficiency and reliability of qualitative analysis in clinical research contexts.
As the AI Product & System Designer, my contributions included:
– Defining the overall system architecture and agent roles
– Designing prompt strategies (zero-shot vs. one-shot) and workflow variations
– Developing evaluation frameworks to measure output quality (e.g., similarity metrics, LLM-based scoring)
– Analyzing results to identify performance gaps and inform iterative improvements
– Generation Agent → generates themes
– Merge Agent → consolidates outputs
– Evaluation Agent → scores quality
– Critic Agent → audits reasoning
– Refinement Agent → improves results
– Multi-Agent Collaboration
Modularized the workflow into specialized agents to enable structured, scalable analysis
– Critic Agent
Added a review layer to improve reliability and reduce bias
– Parallel Runs
Used multi-temperature outputs to balance diversity and consistency
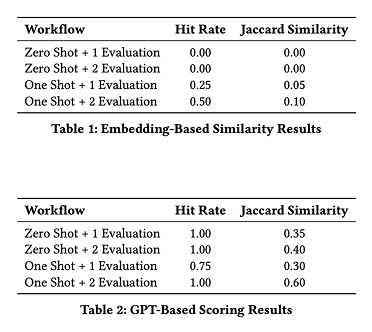
Tested 4 configurations:
– Zero-shot vs One-shot
– Single vs Double evaluation
– Hit Rate: Measures the proportion of human-coded themes that have at least one sufficiently similar theme in the LLM-generated theme set
– Jaccard Similarity: Measures the overlap between the LLM-generated theme set and the human-coded theme set, based on matched theme pairs
– One-shot > Zero-shot
– Double evaluation improves quality
– Critic agent improves consistency
🟣 The quality of AI outputs depends more on how tasks are structured and connected than on any single prompt, especially in multi-step reasoning tasks
🟣 Effective prompt engineering is not about ad-hoc tweaking, but about designing structured, role-specific instructions that align with the overall system workflow